Exponential Family
[References]: CS229 4강을 듣고 정리한 내용입니다~
https://www.youtube.com/playlist?list=PLoROMvodv4rMiGQp3WXShtMGgzqpfVfbU
Stanford CS229: Machine Learning Full Course taught by Andrew Ng | Autumn 2018
Led by Andrew Ng, this course provides a broad introduction to machine learning and statistical pattern recognition. Topics include: supervised learning (gen...
www.youtube.com
일부 내용은 위 probabilistic graphical model강의에서 가져왔습니다!
https://www.cs.cmu.edu/~epxing/Class/10708-20/lectures/lecture05-ParameterEst.pdf
위 강의들을 공부하고 짧게 정리한 내용입니다! 저도 공부하면서 정리한 내용이라 틀린 것이 있다면 언제든 댓글 달아주신다면 감사하겠습니다~ :D
____
이번 포스팅에서는 수학적으로 깔끔하게 정의되는 probability distribution들인 exponential family에 대해 정리해봤습니다. 먼저 exponential family의 정의에 대해 설명하고, 대표적인 경우인 bernoulli 및 gaussian distribution이 어떻게 exponential family form으로 변형되는지 정리해 봤습니다. 또한 exponential family를 이용해 generalized linear model을 정의했을 때 모습 및 장점에 대해서도 간단히 정리해 봤습니다!
1. Exponential Family

exponential family는 probability distribution의 probability density function (이하 PDF)가 위와 같은 식으로 정의되는 distribution들이다. 갑자기 복잡한 식이 나와서 당황스럽겠지만 각 요소가 의미하는 바를 정리해보면,
- y: data이다. 여기서는 output label에 대한 distribution(classification이라면 bernoulli distribution)을 나타낼 것이기 때문에 y로 표기하였다.
- η: natural parameter이다. 이 natural parameter는 각 exponential family에 속하는 distribution들의 parameter로 자유롭게 변형될 수 있다. learning parameter이다.
- T(y): sufficient statistic이다. 결국 T(y)=y가 된다고 한다.
- b(y): base measure이다. y에 대한 함수로 scalar이다.
- a(η): log-partition function이다. 이것 역시 η에 따라 정해지는 scalar이며, 수식 맨 오른쪽 식을 보면 normalizing constant로써 작동하는 것을 볼 수 있다. Z(η) = exp(a(η))이므로 log-partition function이다.
2. Examples
갑자기 위의 식을 왜 소개했는지 예시를 통해 살펴보자!
2.1 Bernoulli distribution
binary data의 distribution을 모델링할 때 쓰이는 bernoulli distribution은 대표적인 exponential family이다. 어떤 사건이 일어날 확률을 ϕ라고 하면, ϕ는 추정할 parameter가 된다. bernoulli distribution의 PDF를 아래와 같이 나타낼 수 있다:

PDF식을 앞서 정의한 exponential family의 PDF form이 되도록 정리하다 보면 최종적으로 위 식의 맨 아래와 같은 형태가 되는데, 결과적으로 b(y)=1, 첫 번째 log 식은 η, T(y)=y, 두 번째 log 식은 a(η)가 되는 것을 볼 수 있다.
그래서 어쩌라는거지? 라는 생각이 들 텐데 아래처럼 식을 정리해보면 새로운 것을 발견할 수 있다:
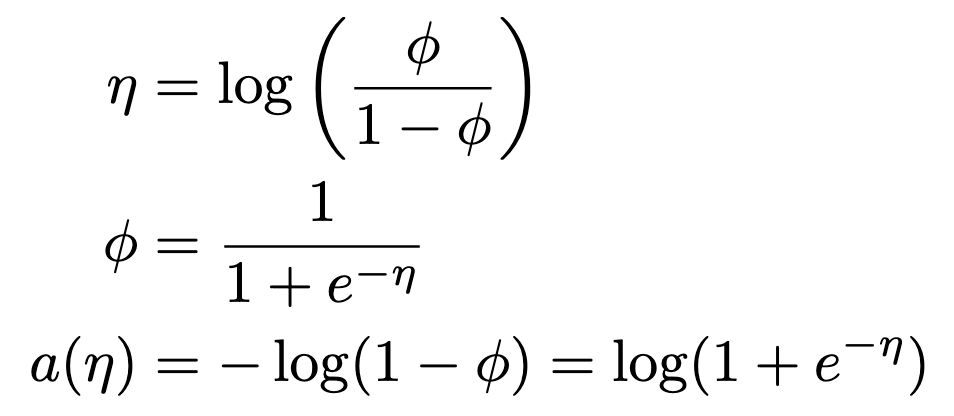
위에서 첫번째 식을 두 번째 식처럼 추정할 parameter ϕ에 대해 정리해보면, η에 대한 sigmoid function이 되는 것을 볼 수 있다. 뿐만 아니라 normalizing constant인 a(η)역시 결과적으로 η에 대해 표현할 수 있다. 즉 η만 learning하면 bernoulli distribution을 modeling할 수 있다는 의미이다.
2.2 Gaussian distribution
두 번째로 gaussian distribution을 살펴볼텐데, variance가 1로 고정된 경우를 가정하자. 이러한 경우 PDF는 아래와 같다:

맨 아래 식은 exponential family form이 되도록 PDF를 정리한 형태이다. exp()좌측 항은 b(y)로 y에만 관한 함수임을 볼 수 있다. exp 내부의 μ는 η, y는 T(y), 1/2*μ^2은 a(η)에 대응됨을 볼 수 있다. 중요한 점은 결과적으로

learning parameter η가 μ와 같으므로 gaussian을 모델링할 때 쓰일 parameter를 η로 정의할 수 있고, normalizing constant 또한 η를 추정함으로써 구할 수 있다는 점이다.
3. Why exponential family?
1) log partion function A(η) 계산을 우회하지 않아도 된다.

결과적으로 exponential family에서의 p(x)는 다음과 같이 나타낼 수 있었다. (헷갈리게 되어있지만 여기서는 log-partition function을 소문자 a에서 대문자 A로 대체했습니다 ㅠㅠ) 그렇다면 일반적으로 우리는 maximum likelihood estimation을 이용해서 log p(x)를 최대화하는 parameter η를 구하게 된다.

즉 위 식을 maximize하게 되는데, 문제점은 log-partition function A(η)이다. 일반적으로 A(η)를 처리하기 위한 다양한 방법이 있는데, 일례로 PGM 포스팅 2편에서 소개한 restricted boltzmann machine처럼 contrastive divergence를 통해 partition function을 구하지 않는 방법이 있다. 신기하게도 exponential family에서는 이런 걱정을 할 필요가 없다.

왜냐하면 gradient descent를 구할 때 θ' = θ + α * dL/dη를 이용해 update하게 되는데, loss를 parameter η에 대해 미분한 식은 위와 같이 생겼다. 문제가 되는 항은 dA(η)/dη인데, 결론적으로 exponential family에서는 dA(η)/dη = μ다.
(1) dA(η)/dη = μ 유도 과정

(2) d^2 A(η)/dη^2 = Var[T(x)] 유도 과정
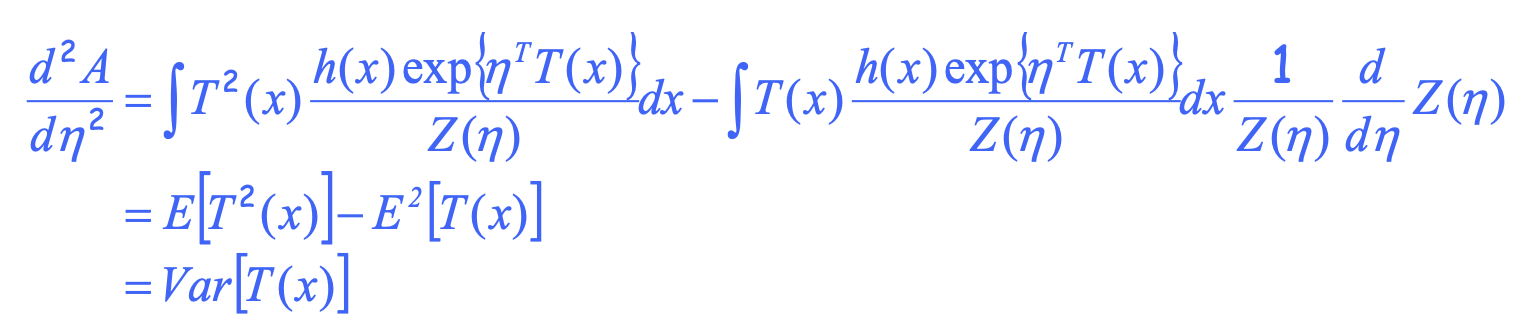
당황스럽겠지만 자세히 보면 그냥 고등학교때 배운 지수함수 미분 적분 내용이다. 결과적으로 exponential family는 log partition function A(η)를 η에 대해 한 번 미분하면 기댓값 E_x~p(x) [x] = μ를 (bernoulli 및 gaussian 예시에서 T(x) = x였다), 두 번 미분하면 variance를 구할 수 있다는 내용이다. 이러한 특징을 moment generating property라고 한다고 한다. 어쨌든 결과적으로 gradient descent과정에서 μ는 데이터를 기반으로 한 empirical expectation으로 대체할 수 있으므로 연산이 가능하다.
2) 결과적으로 negative log likelihood (=loss function)가 convex하다.
위에서 살펴보았듯이, d^2 A(η)/dη^2 = Var[T(x)]이므로 > 0이다. 따라서 A(η)은 convex 함수이고, log p(x)는 concave, -log p(x)는 convex가 된다. 결과적으로 exponential family의 loss function은 convex function이다.
딥러닝은 non-convex optimization이라고 했는데?? 라면서 의문이 들 것이다. 일례로 우리가 딥러닝에서 사용하는 모델들은 거의 대부분 exponential family의 cost 함수를 optimize하고 있다. 예를 들어 language model이나 classification model이라면 categorical distribution이므로 bernoulli를, diffusion같은 이미지 생성 모델이라면 gaussian을 기반으로 하고 있다. 그럼 이런 모델들이 모두 convex optimization이었던 것일까?
결과적으로는 아니라고 한다. model 구조가 아주 간단한 경우 (ex. logistic regression처럼 linear만으로 parameter를 추정하는 경우, Section 5에 설명) convex optimization이 될 수 있다. 하지만 모델을 깊이 쌓을수록 모델 구조가 복잡해지기 때문에 convex하다고 보장할 수 없다고 한다. 자세한 설명은 아래 링크에 나와있다.
Is Cross entropy cost function for neural network convex?
My teacher proved that 2nd derivate of cross-entropy is always positive, so that the cost function of neural networks using cross entropy is convex. Is this true? I'm quite confuse about this becau...
stats.stackexchange.com
4. exponential family 종류
- real value를 추정할 때: gaussian distribution
- binary variables 다룰 때: bernoulli distribution
- count problem: poisson distribution
- 양수인 실수를 다룰 때: gamma, exponential distribution
- probability distribution에 대한 probability distribution을 모델링(bayesian): beta, drichlet distribution
5. Generalized linear models with exponential family
이제 exponential family에 대해 왜 알아봤는지 application을 통해 알아보도록 하겠다. Section 2.2에서 η를 gaussian parameter μ에 대한 function으로, μ를 η에 대한 function으로 나타낼 수 있음을 보였다 (gaussian말고도 다른 distribution에도 해당된다). 이것을 함수로 아래와 같이 표현할 수 있다:
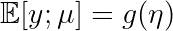
: canonical response function
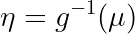
: canonical link function
각각의 함수를 부르는 이름은 위와 같고, 결과적으로 함수 g의 형태로 각각의 parameter로 변형할 수 있음을 나타낸 것이다.
결과적으로 exponential family의 model parameterization은 아래와 같이 이루어진다:
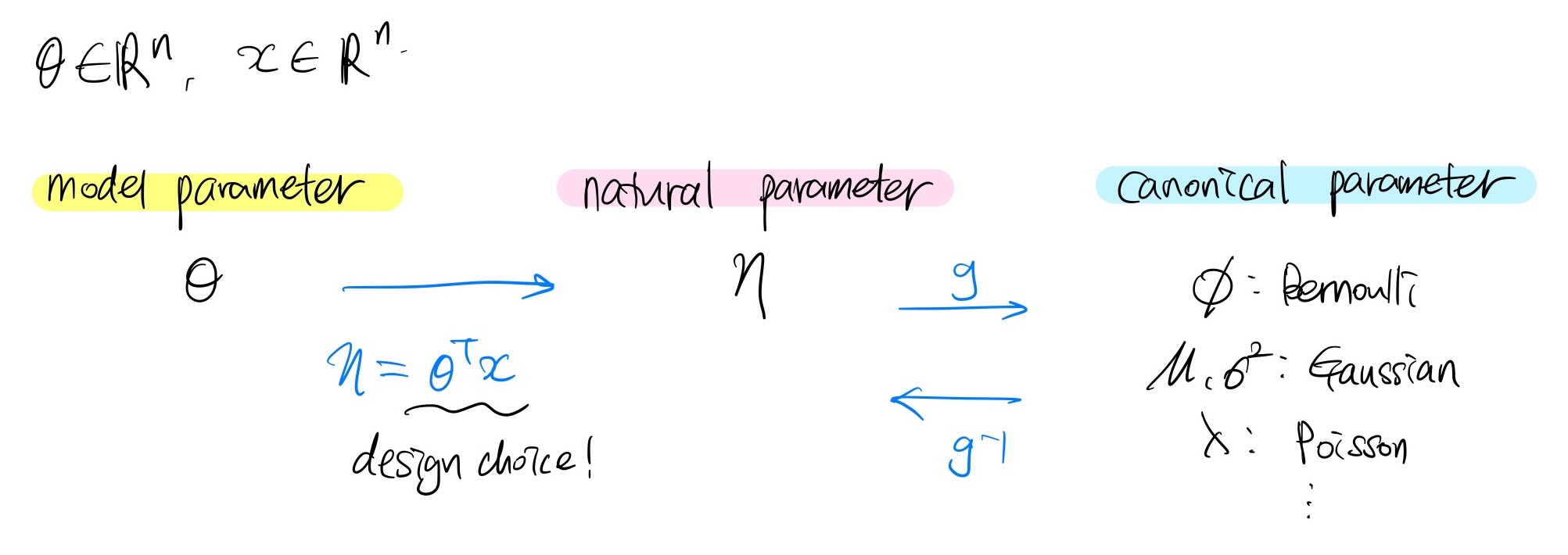
보통 model parameter θ를 learning하게 되는데, 이 때 어떤 design choice에 따라 θ를 natural parameter η로 mapping할 수 있다. 결과적으로 이러한 과정을 통해 η만 추정하게 되면 bernoulli, gaussian, poisson distribution 등에 쓰이는 parameter들을 모두 추정할 수 있게 된다.
일례로 logistic regression을 살펴보자. logistic regression은 discriminative learning 알고리즘이므로 bernoulli distribution을 모델링한다. bernoulli distribution에서 parameter ϕ는 아래와 같이 η에 대한 sigmoid로 표현할 수 있었다. 결과적으로 η는 맨 오른쪽 식에서와 같이 linear model로 추정할 수 있는데, 이것이 바로 확률값으로 변환하기 전 pre-probabilistic값인 logit을 의미하게 된다.
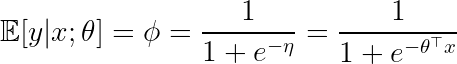
딥러닝이 logistic regression으로부터 출발했고, logistic regression을 깊이 쌓는 것에서 deep neural network가 나왔다는 것을 잘 알고있을 것이다. 결과적으로 만약 transformer라면 바로 위 수식과 유사하게 logit을 통해 softmax(sigmoid)를 적용하는 것도, diffusion이라면 모델을 통해 μ를 추정하는 것도 모두 이와 같은 exponential family에서 bernoulli/gaussian/... distribution을 parameterize하는 것에서 출발했다는 것을 알 수 있었다.